Apache Kylin是一个开源的分析型数据仓库,为 Hadoop 等大型分布式分析平台之上的超大规模数据集(PB级)通过标准 SQL 查询及多维分析 ( OLAP ) 功能,提供亚秒级的交互式分析能力。
Cube 是 OLAP ( Online Analytical Processing ) 的核心数据结构,把维度和度量抽象为一个多维模型,赋予了OLAP 新的数据组织和存储形式,并可以快速、高效地完成 OLAP 的多维分析操作。
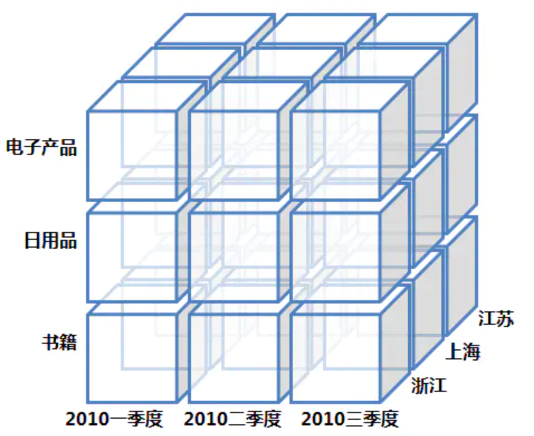
我们可以想象有一个三个维度的 Cube,它包含了商品种类、时间和地点。在存储中我们可以把某一个具体的小方块想象成一个特定维度组合的度量,左下角的小方块存储了(浙江,2010 第一季度,书籍)这个组合下我们关心的业务指标, 这可能是成交总量、平均价格等等。基于这样的数据结构,我们可以完成钻取、上卷、切片、切块和旋转的操作,这样就可以进行一些数据分析、数据探索,帮我们去解答这些业务的问题。并且由于不需要现场进行扫描和聚合,所以查询响应一般很快。
Apache Kylin 通过构建引擎和查询引擎来分别生成和查询预计算数据文件,并且基于分布式计算引擎如 Apache Spark 来扩展构建引擎和查询引擎的计算能力。对于用户,Kylin 提供不同的接口如 SQL/HTTP/BI/Excel 等方式来进行数据分析,可以使得用户可以对 PB 级数据集实现秒级查询。
本文将简单介绍从Kylin中构建Cube的过程,包括数据预处理、模型设计、Cube构建等步骤。
数据清洗包括去除数据中的噪音和异常值,处理缺失数据等。具体步骤如下:
- 去除噪音和异常值:利用统计方法或机器学习算法识别并删除或修正数据中的噪音和异常值。
- 处理缺失数据:使用均值填充、插值法或其他方法处理缺失数据,确保数据的完整性
数据转换是将数据从原始格式转换为适合分析的格式。常见的转换操作包括:
- 数据类型转换:将数据类型转换为适合分析的类型,例如将字符串类型的日期转换为日期类型。
- 归一化和标准化:对数据进行归一化或标准化处理,以消除不同尺度的数据对分析结果的影响。
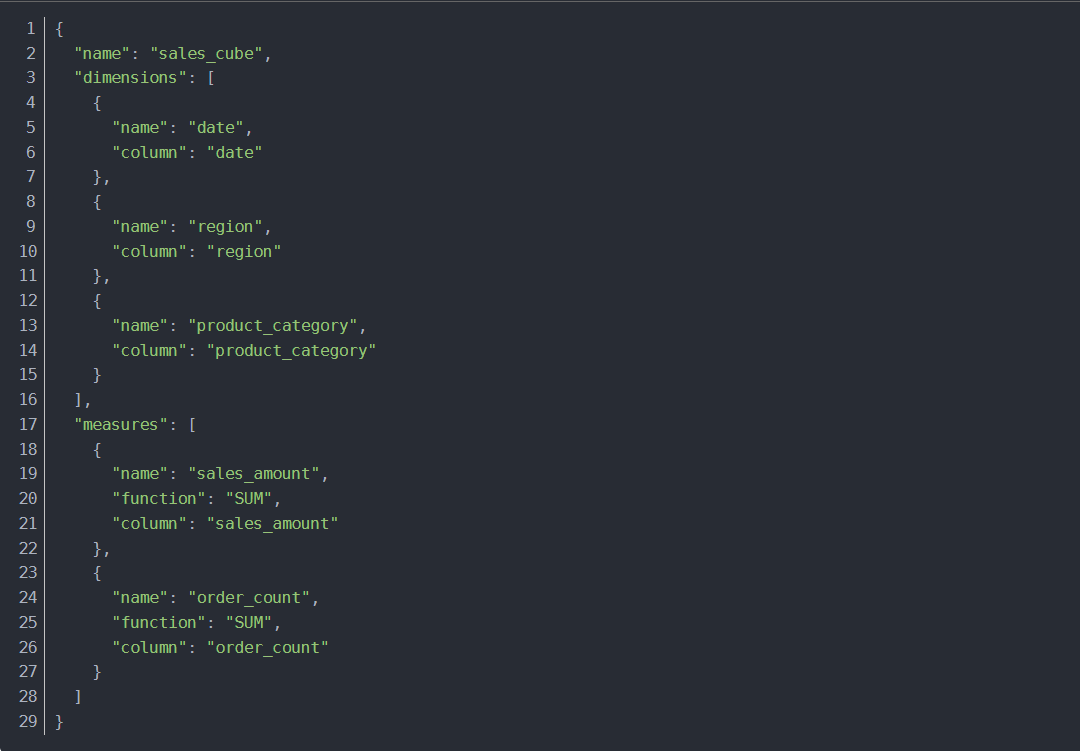
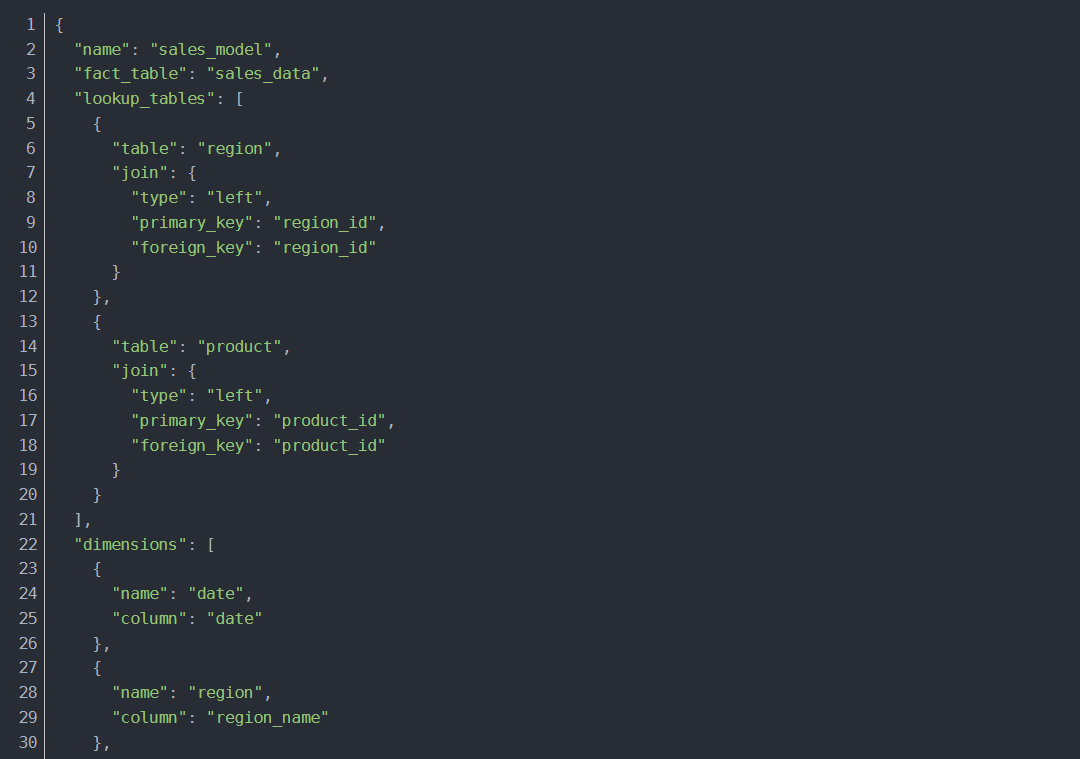
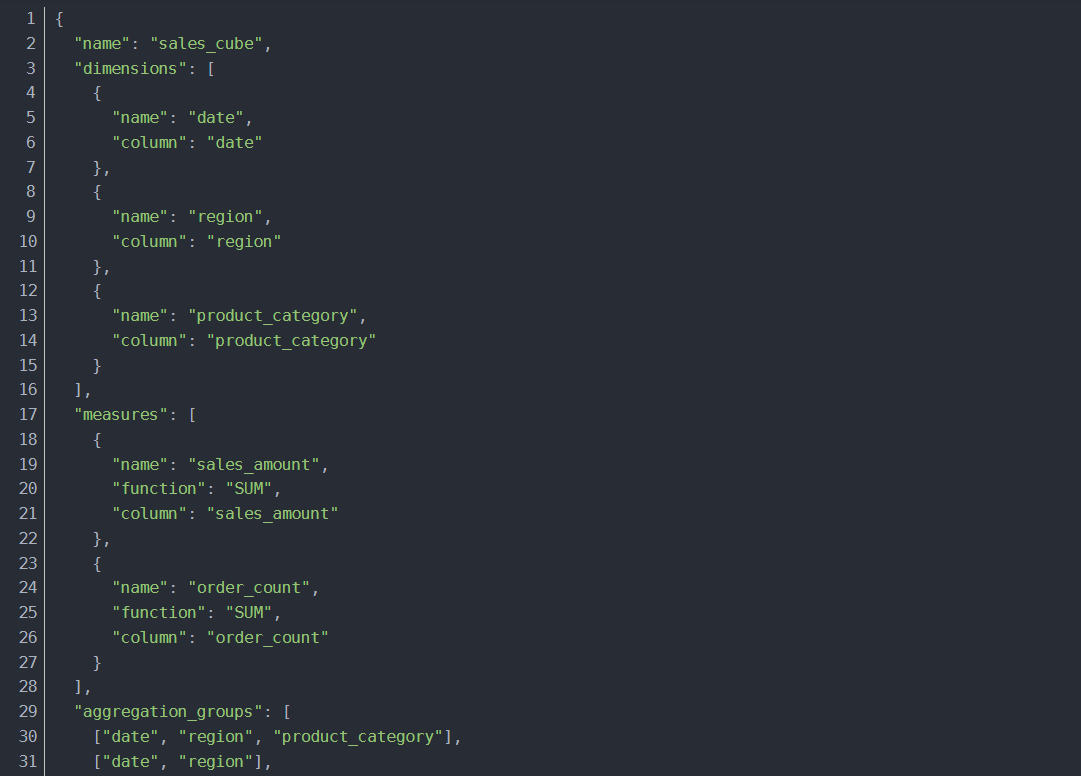
Cube构建优化
为了提高Cube的构建效率和查询性能,可以进行以下优化:
四、查询和分析
Cube构建完成后,可以通过Kylin提供的SQL查询接口进行数据查询和分析。
SQL 查询
Kylin支持标准的SQL查询,通过SQL语句可以方便地对Cube进行数据查询。例如,可以通过以下SQL语句查询某一时间段内的销售额:
SELECT SUM(sales_amount)
FROM sales_cube
WHERE date >= '2025-01-01' AND date <= '2025-12-31'
数据可视化
为了更直观地展示数据分析结果,可以使用BI工具对查询结果进行可视化。Kylin兼容多种BI工具,如Tableau、Power BI等,用户可以通过这些工具创建图表、报表等,辅助决策分析。




