业务场景描述:
在数据处理流程中,当系统输出多笔独立数据后,通过数据状态标识触发多任务并行链路。每笔数据分别匹配至独立任务节点执行处理(实现数据隔离与任务定制化执行)。待各任务完成处理后,通过统一的数据状态校验节点完成结果收敛,最终将多笔数据合并至单一任务节点进行后续集成处理。
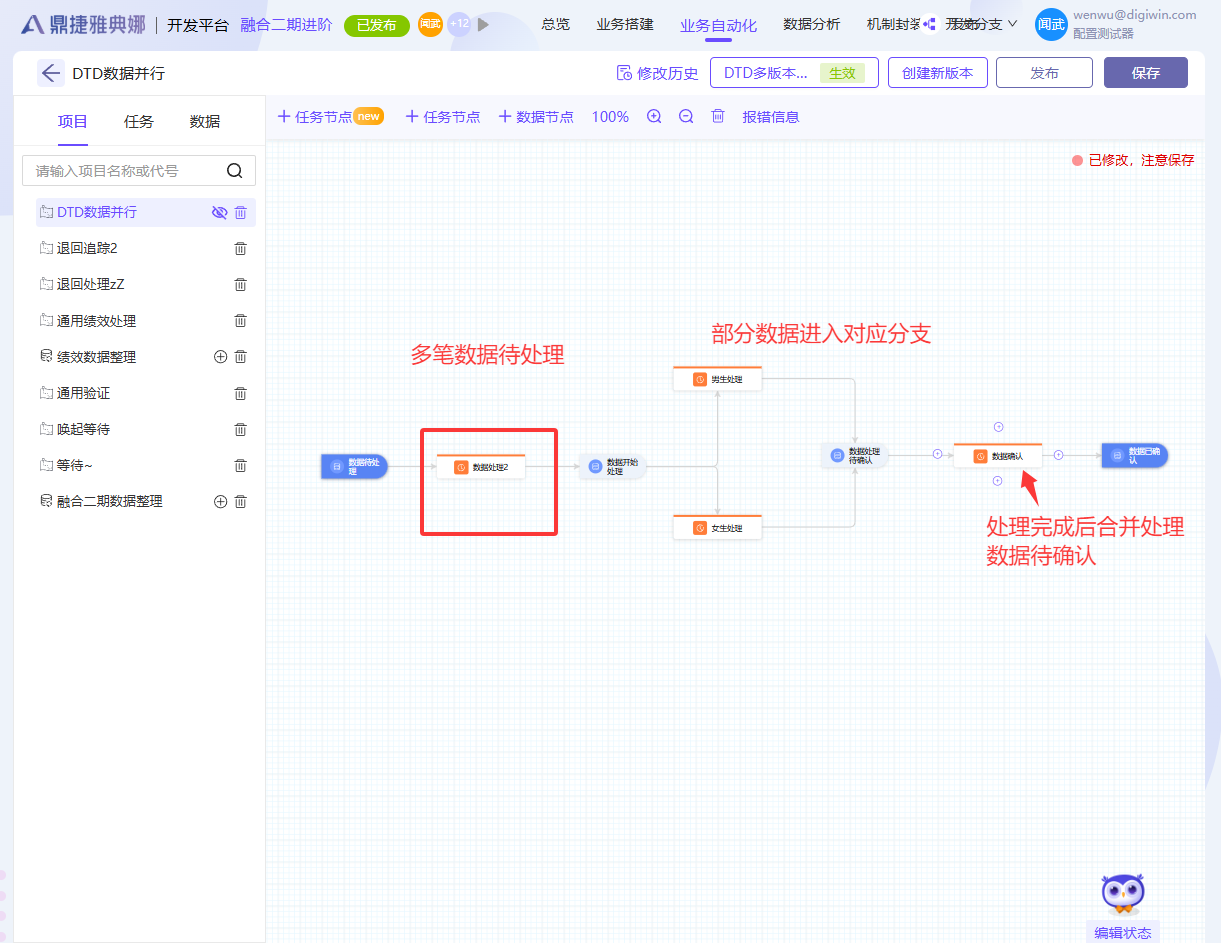
1. 数据准备,配置形成DTD画布
根据实际业务场景,配置项目,任务,数据并在画布连接形成DTD片段。
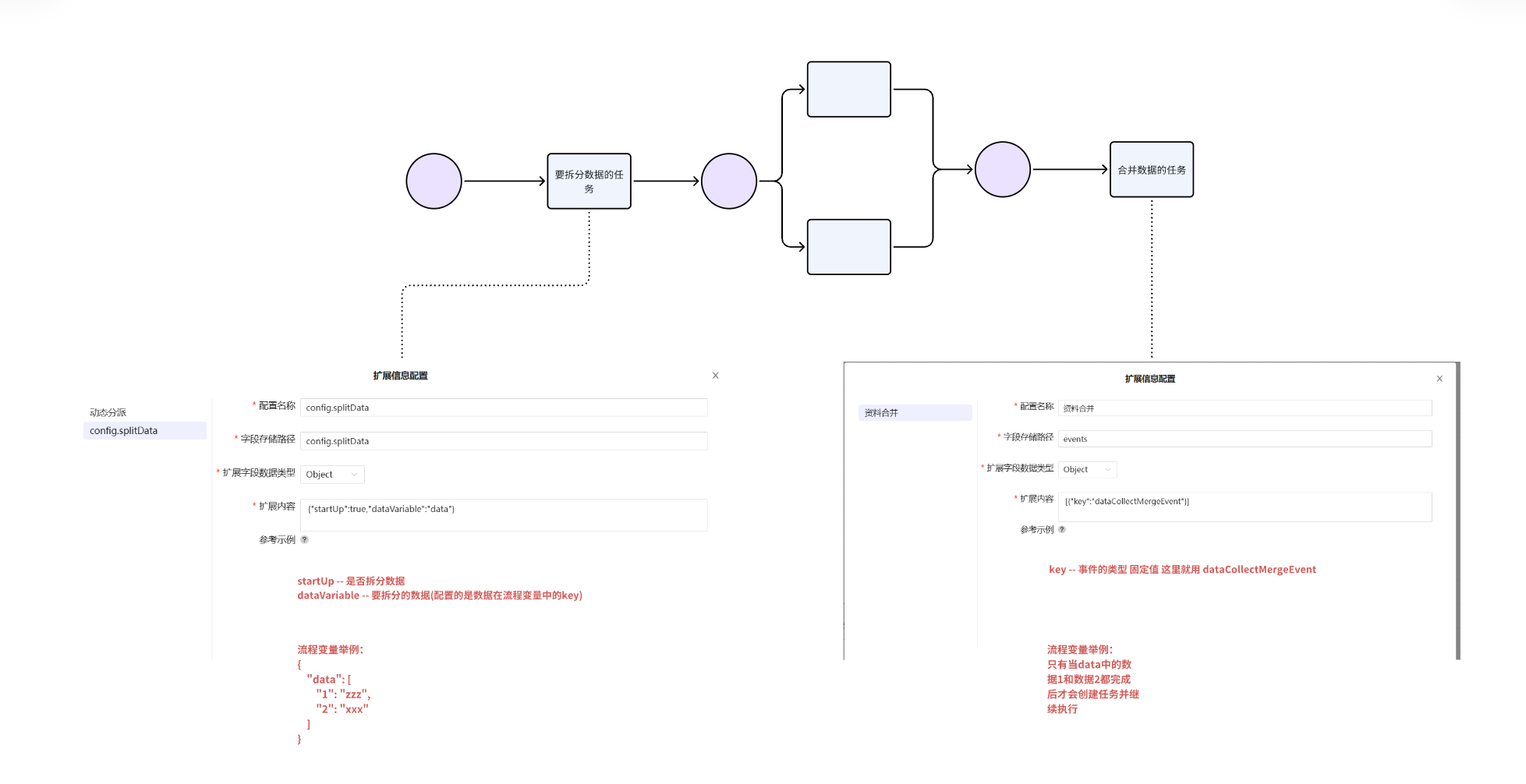
如图所示,配置了一个多笔数据处理后,根据数据中性别需要分配到不同的关卡处理,在处理完成后合并处理数据,推送确认信息
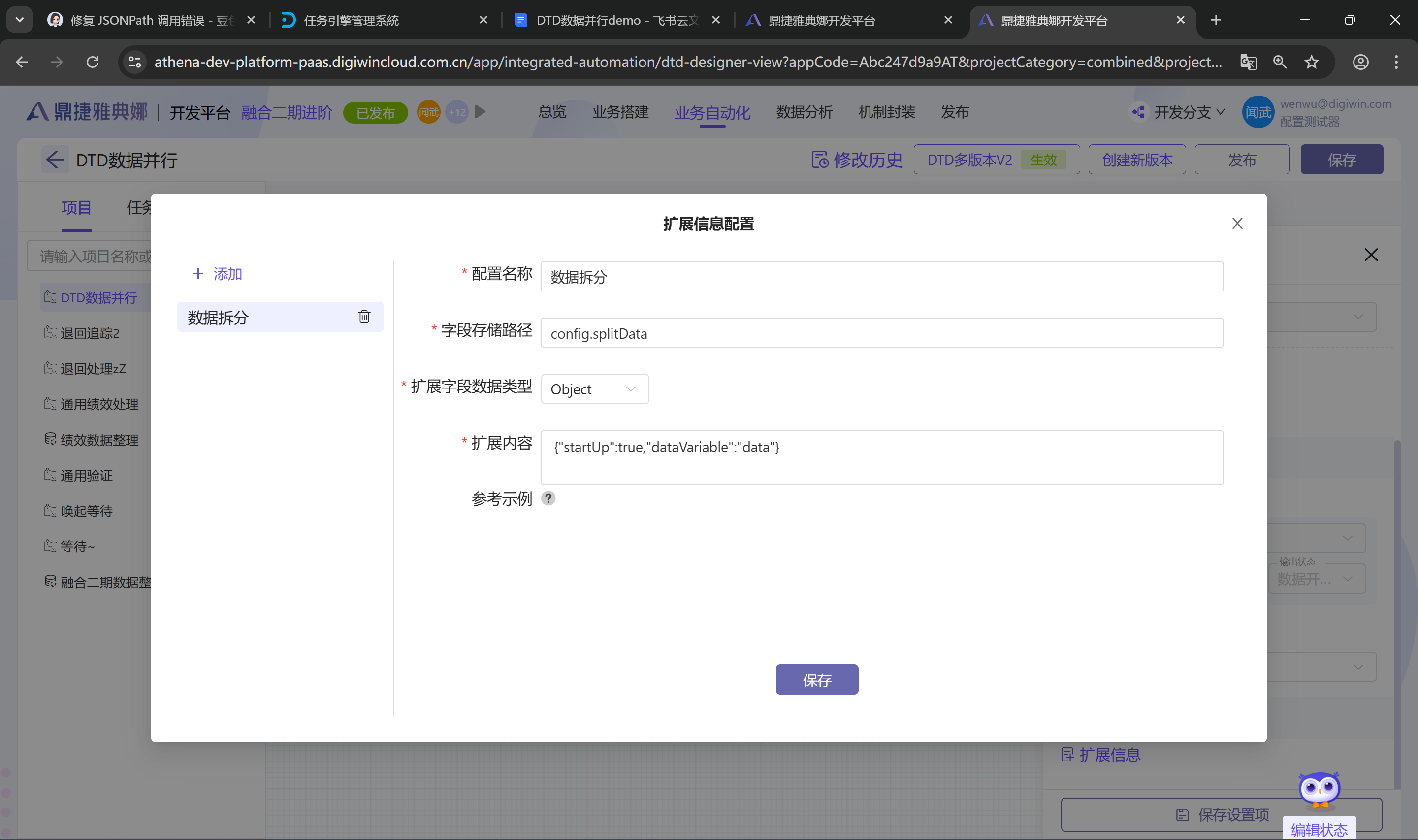
2.数据拆分任务配置扩展信息
根据实际场景,选中需要进行数据拆分的任务,点击进行扩展配置
完成配置后,编辑保存扩展配置
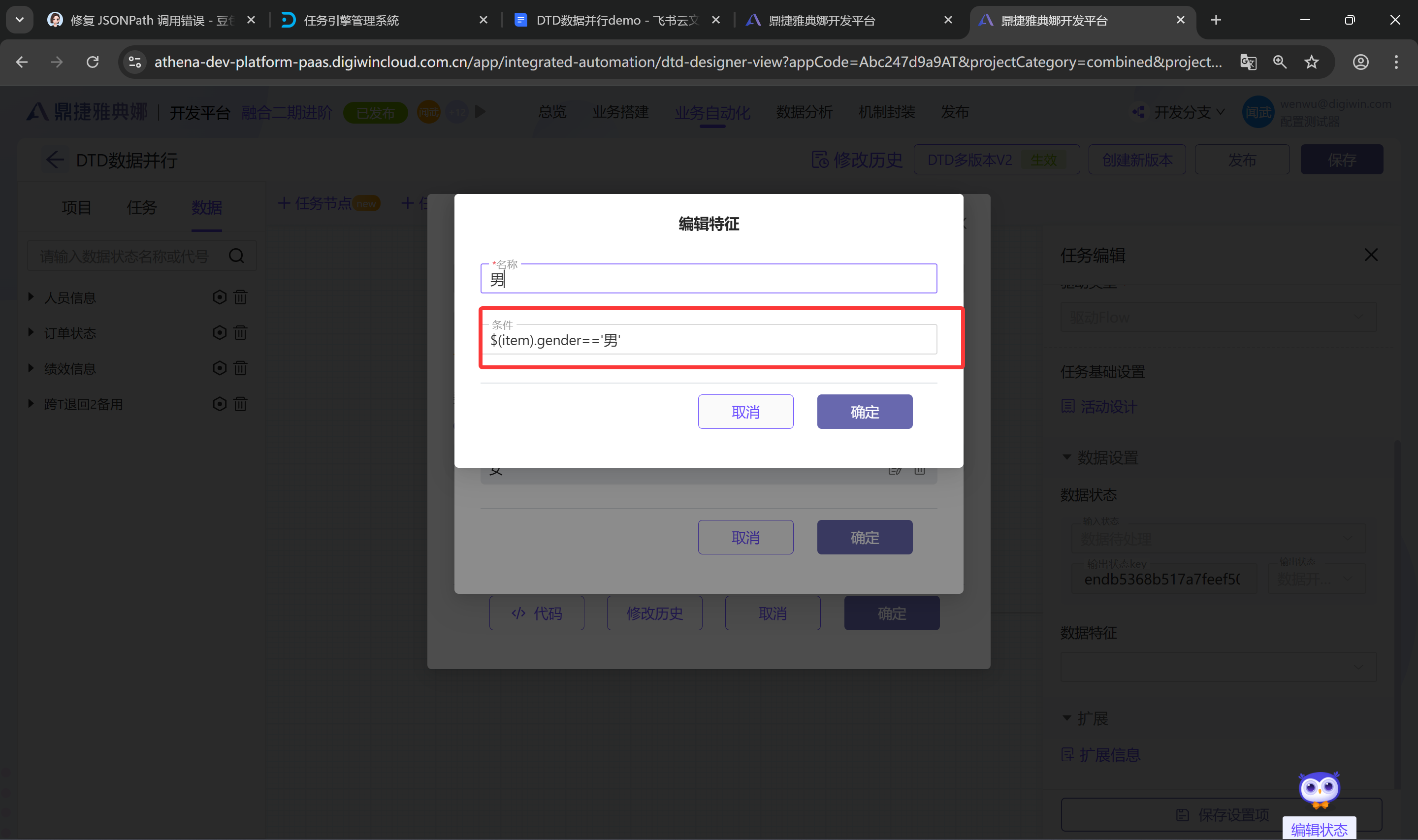
3.根据拆分场景配置数据特征关联数据状态与任务
根据拆分的业务场景,配置数据特征,例如此处要根据性别去查分数据,点击设置数据,数据配置特征级为性别,特征集配置男女特征,并结合数据配置男女特征表达式;

4.配置数据合并扩展信息
根据业务场景,选中需要进行合并场景任务,点击扩展配置任务扩展配置,参照下图
5.检查配置发版运行
完成配置,编译发布,运行项目
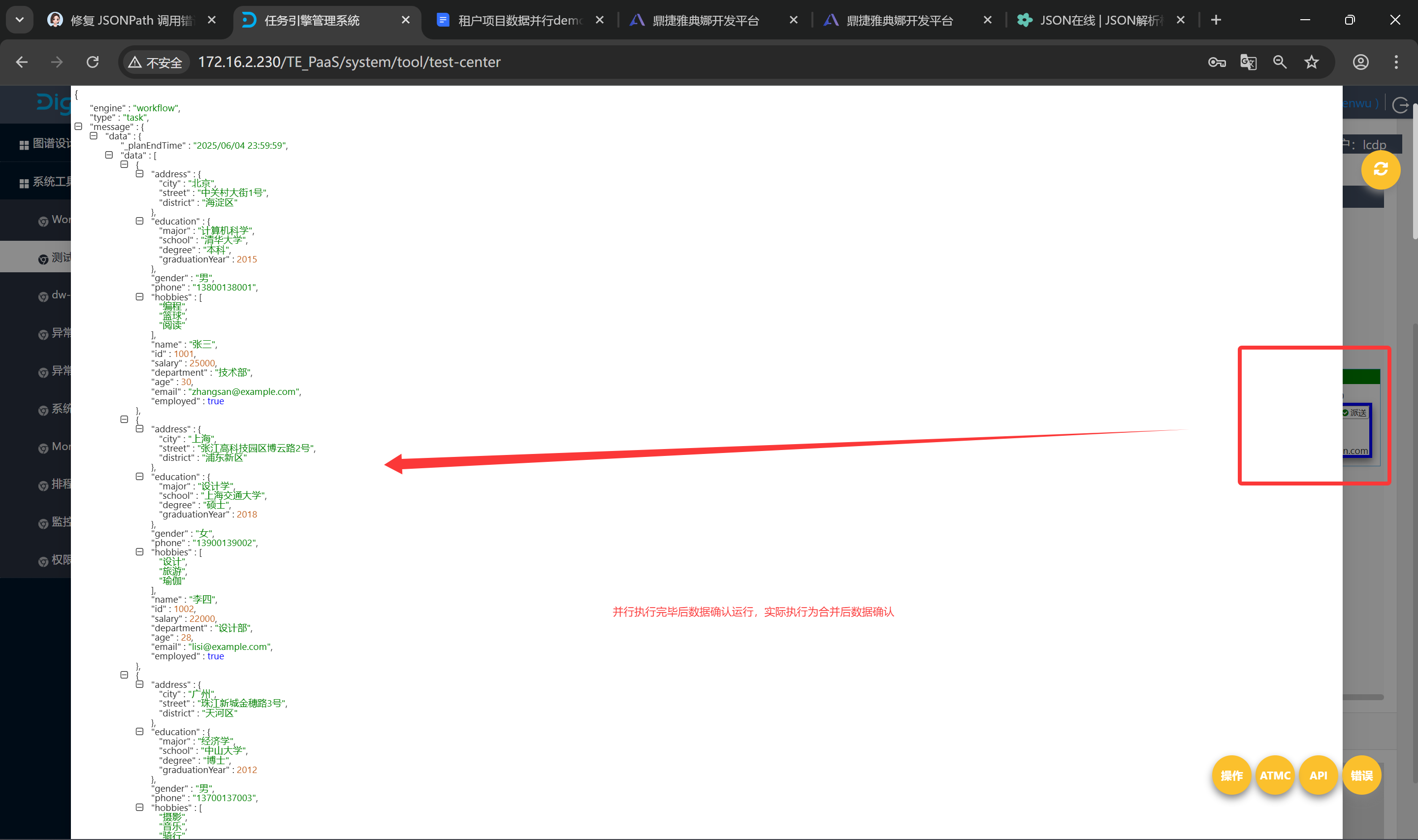
发起项目数据参考如下
paas区实例参考:invoke1839851418400342016
[{
"address": {
"city": "北京",
"street": "中关村大街1号",
"district": "海淀区"
},
"education": {
"major": "计算机科学",
"school": "清华大学",
"degree": "本科",
"graduationYear": 2015
},
"gender": "男",
"phone": "13800138001",
"hobbies": ["编程", "篮球", "阅读"],
"name": "张三",
"id": 1001,
"salary": 25000,
"department": "技术部",
"age": 30,
"email": "zhangsan@example.com",
"employed": true
}, {
"address": {
"city": "上海",
"street": "张江高科技园区博云路2号",
"district": "浦东新区"
},
"education": {
"major": "设计学",
"school": "上海交通大学",
"degree": "硕士",
"graduationYear": 2018
},
"gender": "女",
"phone": "13900139002",
"hobbies": ["设计", "旅游", "瑜伽"],
"name": "李四",
"id": 1002,
"salary": 22000,
"department": "设计部",
"age": 28,
"email": "lisi@example.com",
"employed": true
}, {
"address": {
"city": "广州",
"street": "珠江新城金穗路3号",
"district": "天河区"
},
"education": {
"major": "经济学",
"school": "中山大学",
"degree": "博士",
"graduationYear": 2012
},
"gender": "男",
"phone": "13700137003",
"hobbies": ["摄影", "音乐", "骑行"],
"name": "王五",
"id": 1003,
"salary": 35000,
"department": "市场部",
"age": 35,
"email": "wangwu@example.com",
"employed": true
}]
运行拆分数据时,成功根据数据特征拆分数据并拆分数据进入到对应分支
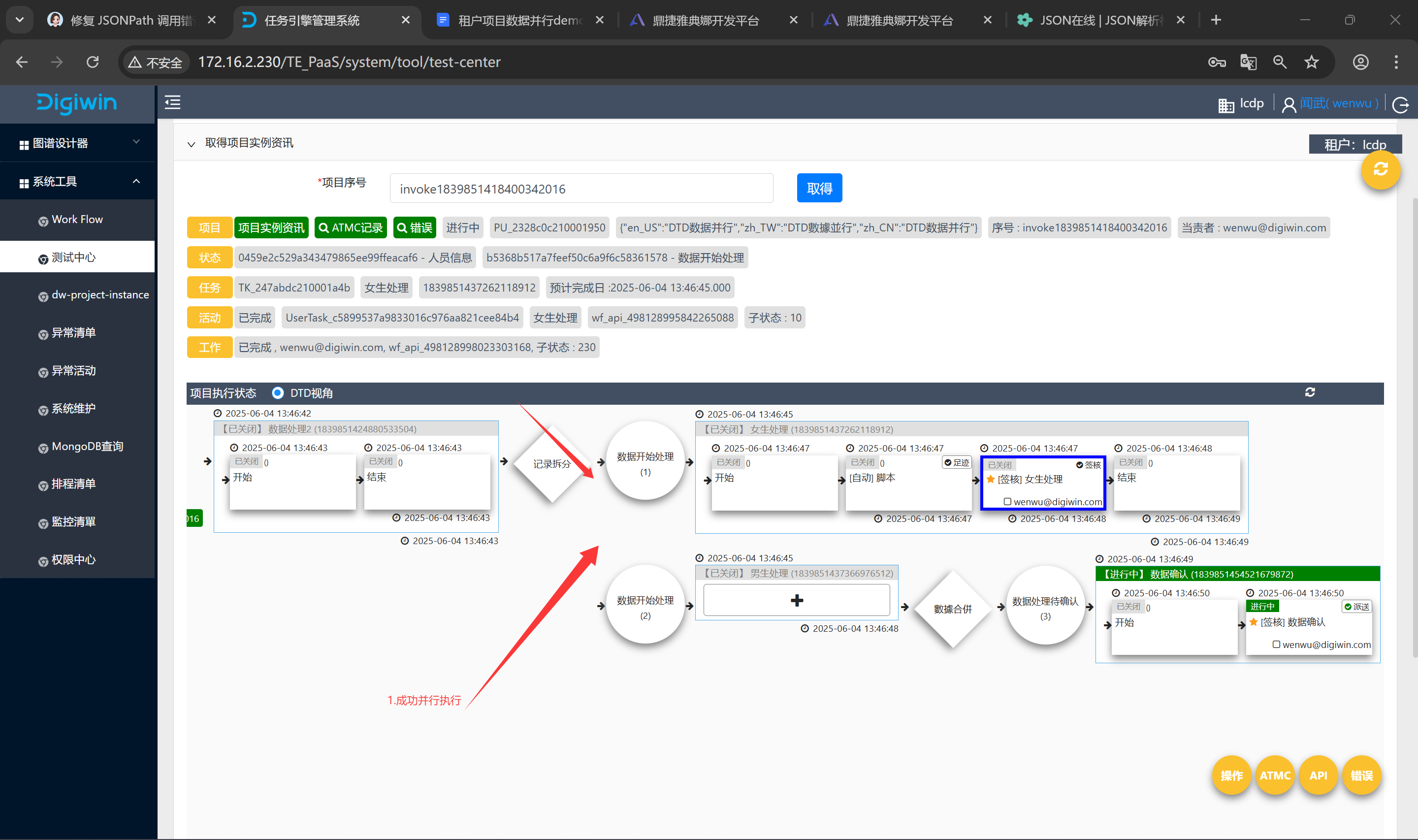
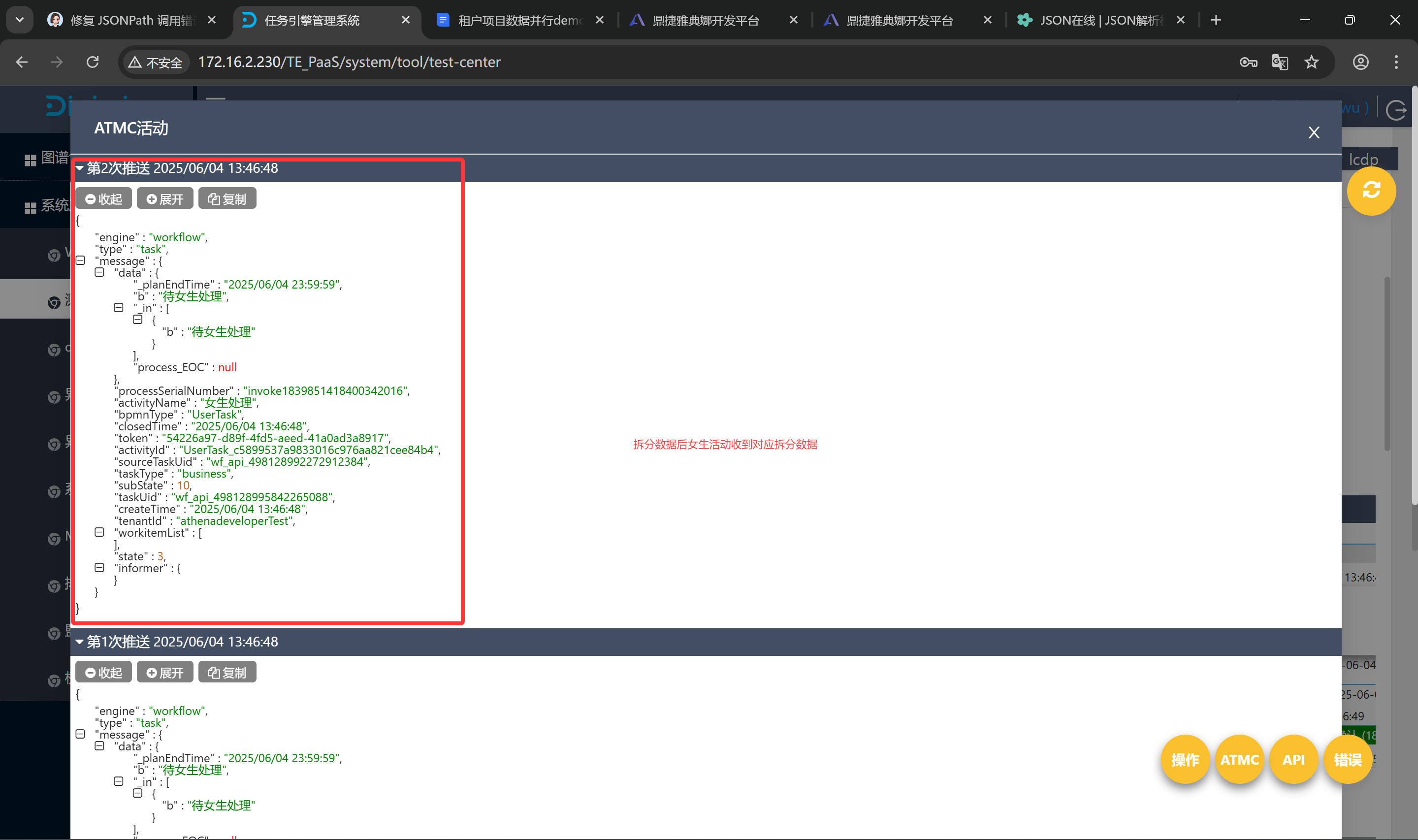
对应分支执行完毕后,数据成功合并进入下一个节点