娜娜对类似含义的话术,识别的准确率好像不同,请问这是什么问题导致? |
|
问答
紧急程度
最佳答案 | |
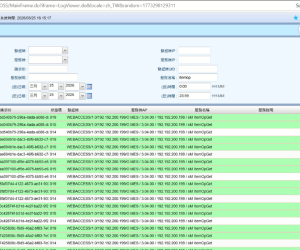 纪录呈现绿色是什么意思呢?~按了没反应呢84 人气#互联中台(CROSS EAI)
纪录呈现绿色是什么意思呢?~按了没反应呢84 人气#互联中台(CROSS EAI)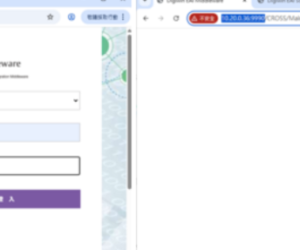 中台登入出现:授权服务失效,请向客户服务74 人气#互联中台(CROSS EAI)
中台登入出现:授权服务失效,请向客户服务74 人气#互联中台(CROSS EAI)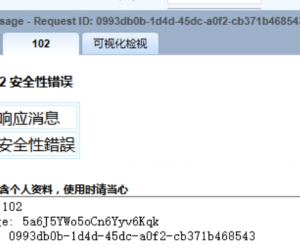 中台呼叫報錯:102 安全性錯誤95 人气#互联中台(CROSS EAI)
中台呼叫報錯:102 安全性錯誤95 人气#互联中台(CROSS EAI)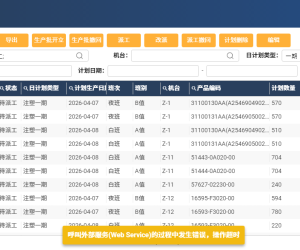 呼叫中台报错:呼叫外部服务过程发生错误,106 人气#互联中台(CROSS EAI)
呼叫中台报错:呼叫外部服务过程发生错误,106 人气#互联中台(CROSS EAI)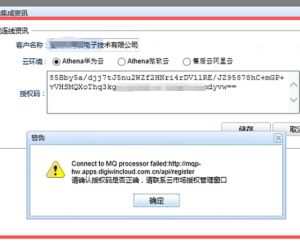 云地中台注册报错:Connect to MQ processo70 人气#互联中台(CROSS EAI)
云地中台注册报错:Connect to MQ processo70 人气#互联中台(CROSS EAI)
